How The Web Works

Hmm… I see you made it here. Welcome, I’m guessing you probably clicked a link somewhere and it brought you here, well if that's the case then congratulations you already know a lot about the web, like how to navigate your way around. But do you know how it works? Do you know what happened when you clicked that link? I know you’re probably wondering, yeah that's right, what happened? 🤷🏼♂️🤷🏼♂️🤷🏼♂️ Little worries, I’m going to explain that concept in this post, but we can’t talk about how the web works without first of all talking about the internet so let's start from there.
THE INTERNET:
Invented over 40 years ago a system architecture that has transformed communication and the flow of information, by allowing various computers to connect through a global network that relies upon the TCP/IP protocol it grants over 4billion people access and has millions of devices connected to the internet at every point in time. It is a major driving force in our world today.
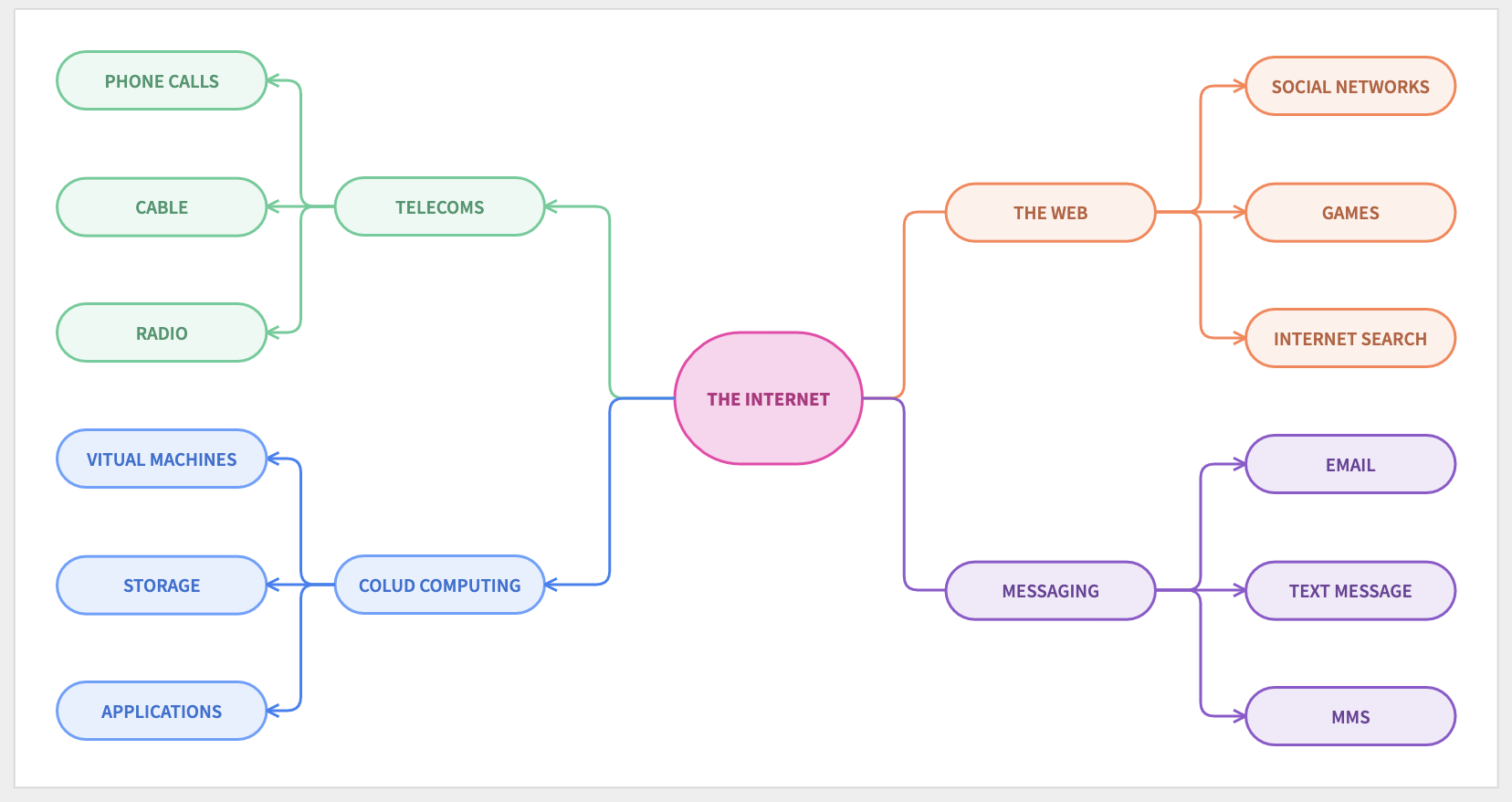 Applications of the internet
Applications of the internet
HISTORY OF THE INTERNET:
It consists of technologies developed by different people and organisations. On October 29, 1996, ARPANET, the first host-to-host network connection was established. It connected principal universities and government support research sites. It was created by the Advanced Research Project agency of the United States Department of Defence. It was the first general-purpose communications network. It wasn't until the 1970s that the internet got a huge transition thanks to the invention of TCP/IP architecture which improved how information was sent and received over the web, making delivery more consistent regardless of range and mode of connection.
HOW DOES THE INTERNET WORK:
Now we’ve gone through some history lessons, let's see how the internet works. The internet enables computers connected via a network to transmit data and information between one another. To make this possible it uses the TCP/IP protocol(explanation coming up.) As mentioned earlier to maintain the flow of information, this protocol governs the flow of information from one connected computer to another.
WHAT IS TCP/IP:
IP: Stands for Internet protocol, it is a unique identifier for every device connected to the internet. It is usually a string of numbers separated by periods called Octets. E.g “192.168.78”. The IP has two versions namely:
- IPV4
- IPV6
IPV4 is the first version and the most widely used to identify devices on the internet. However the IPV4 supports a 32-bit system and it is limited to about 4 billion unique addresses, sounds like much right? Haha think again cos presently there are over 4 billion devices connected to the internet already, ranging from phones to laptops to microwaves and even fridges all add up to the number and it keeps increasing. The IPV4 could not contain all the devices hence IPV6 was created. IPV6 was developed by the Internet Engineering Task Force(IEFE). Unlike its older brother IPV4 which supports a 32-bit system the IPV6 boosts a 128-bit system and can generate about 3.4x1038 addresses. Please don't ask me to name it, I usually stop naming once it gets to the trillion marks. Now let's talk about TCP.

WHAT IS TCP:
Stands for transmission control protocol, it works with IP to make sure that the transfer of information is dependable. It makes sure information is not lost in transit. It was first published in 1973 by Robert.E. Kahnand Vinton G. Cerf as part of a research paper but was standardised 8 years later. TCP works by allowing the transfer of information in both directions between connected devices. This means computers connected via TCP can both send information to one another at the same time. TCP breaks the information being transferred into segments called packets, each packet also carries information such as the IP address of the destination computer. By convection the two computers connected via TCP are called Client and Server, it doesn't matter which computer is called the client or the server but each must have an IP address and a port(usually the client initiates communication by sending a request to the server). The packets are assembled properly in the destination system. So IP identifies each device, TCP enables the flow of information.
Now putting it all together let’s see what happens when you enter a web address in your browser.
How The Web Works:
Now that we’ve got a good understanding of the components that the web relies on, let's get to know how the web really works.
First: The PC/mobile phone making the request has to be connected to the internet through your Internet Service Provider(ISP) via WIFI, modem, or your sim card. This means that most times we are not connected to the internet directly, instead we are connected to our ISP which grants us access to the internet based on some conditions like you buy a subscription plan, etc.
Second: You type in a web address known as Uniform Resource Locator(URL) in the search bar, it looks like this: http://www.website.com/index.html, you normally type the part without the “http://www.” part because browsers are now smart enough to add it automatically for you. Every website has its own unique URL, and it is divided into at least 3 parts namely
- Protocol/Scheme
- Domain name
- Path to the resource

image credit Developer.mozilla.org
Protocol/Scheme: Protocols are rules that govern how data is transferred between two systems or within a system itself. The web uses the HTTP protocol and according to the Mozilla Developer Network(MDN) HTTP is an application-layer protocol for transmitting hypermedia documents, such as HTML. HTTP protocol was specially designed for the transfer of information like html documents between client and server. It was built based on the TCP/IP protocol that is used by the internet. It has a twin brother HTTPS which uses Secure Sockets Layer (SSL) or Transport Layer Security (TLS) as a sublayer under regular HTTP application layering; it encrypts and decrypts user HTTP requests to prevent unwanted access. That's why it's always advisable to submit passwords and forms via HTTPS. It works in a request response system where a client sends a request and awaits a response from the server. When the client(user) sends a request to the server through the browser the HTTP protocol establishes a connection with the server and sends the request to the server and it keeps the connection open and waits for a response before closing the connection. Note that getting no response from the server can itself be a response. It has two versions namely:
- HTTP 1.1
- HTTP/2
It has different codes to determine the status of the request, here’s a summarised list:
- Informational responses (100–199)
- Successful responses (200–299)
- Redirects (300–399)
- Client errors (400–499)
- Server errors (500–599)
Different actions a request can ask the server to perform includes:
- GET
- PUT
- POST
- DELETE
This is often referred to as CRUD(Create Read Update Delete) operation.
Domain Name: A domain is just a mapping over the servers IP address, as mentioned earlier every computer has a unique IP address which is a string of numbers. Imagine that every time you wanted to google something you had to type something like 139.132.3.7 in your browser's address bar, doesn't look good right?
 It's because of this reason that domain names were created, to provide a human readable mapping to IP addresses.
It's because of this reason that domain names were created, to provide a human readable mapping to IP addresses.
Path to resource: This is just a pointer to the file you requested on the server, because the server is just like a normal computer, just a little more powerful, so resources are also stored in folders and you need to point to the exact file you want. In modern times and in the world of Single Page Applications(SPA) and Application Programming Interface(API), the path to the file doesn't really point to a document on the server, instead it's called a route, and it is to be handled by the server. TIP: if it ends in an extension like .html, .json, .php etc then it is a path to a document.
Third: After entering the URL and clicking the enter button, your browser looks up the domain name you typed in.
Fourth: If the Domain name is not found it returns an error, else, if the Domain name is found your browser sends an HTTP request to the target server requesting the resource on that path specified in the URL
Fifth: If the server approves the request, it sends a 200 status message(status 200 is a success message).
Sixth: Your browser receives the information, usually an HTML document and parses the page and draws the website on your screen.
Seventh: Taa daa… and that's how you see this stuff on your screen right now.
